Not Again, MingLiu!
長話短說,從 FreeType 2.4.4 (2010-11-28 release) 開始,只要編譯的時候有 啟用 BCI (Byte Code Interpreter) ,新細明體就不應該會破掉了,只是因為一 些原因 (下面詳述),一直到 2.4.5 (2011-06-24 release) 才算是完全解決。
這個問題牽扯到許多有趣知識,所以我決定作個筆記以免以後忘掉。
TrueType
首先是一些名詞解釋,TrueType 是常見的字型 (font) 格式,由 Apple 發展, 後來被 Microsoft 採用並發揚光大;雖然沒有經過任何國際組織的標準化,在當 時儼然已經成為業界標準 (de facto standard)。
TrueType 使用的檔案格式又稱為 sfnt 格式,由許多不同的表格 (table) 組
成,每個表格由四個字的標籤 (tag) 表示,其中我們最關心的是 glyf 這個表
格,因為所有的字符 (glyph) 都儲存在這個表格內。每個字符僅僅紀錄了形狀,
要知道某個編碼的某個字元 (character) 是對應到哪個形狀,還要透過 cmap
這個表格來查詢;也有一個字沒有相對應的字符,或是沒有任何字對應到某個字
符的情況。
參考資料:
Hinting (Instructing)
TrueType 是一種外框字型 (Outline Font),也就是說每一個字符都是以向量圖 形的方式呈現,理論上可以在各種不同解析度下呈現相同的形狀。


但是越是在低解析度的時候,由於可用的像素較少,越容易遇到邊界的表達能力
問題,如右圖的 M 字,若沒有對齊像素點的話,呈現出來的圖案就會比較瘦長
且左右不對稱,如果稍微向右移動並加寬一點,呈現出來的圖案就會比較接近原
本向量圖形所預期的形狀;這個動作正是 Hinting 中的對齊格線 (grid
fitting) 功能。
在 TrueType 檔案中,描述 Hinting 的方式其實是儲存在字型的 fpgm 與
prep 表格中的小程式,或是內嵌在字符中。看起來像是這樣:
PUSHB[000] # Push one byte onto the stack.
3 # Value for loop variable.
SLOOP[] # Set the loop count to 3.
PUSHB[002] # Push three bytes onto the stack.
5 # Point number.
46 # Point number.
43 # Point number.
ALIGNRP[] # Align the points 5, 46 and 43 with rp0 (point 8). This will
# align the height of the two lower serifs. 使用這個小程式的方法是 Apple 的專利,但是因為 TrueType 一開始只是業界標 準,Apple 並沒有在規格書裡面提及專利的相關資訊,造成後來使用 FreeType 啟用 BCI (Byte Code Interpreter) 可能會侵犯專利的問題。(相關專利已經在 2010 年 4 月全數過期)
對每個字符做 Hinting 是個耗時耗力的工作,就算是只有數百個字符的西文字 型也要花上數倍於繪圖的時間來做 Hinting,因此除了少數高品質的字型外,多 數的字型是沒有 Hinting 的。而隨著顯示裝置的解析度越來越高,對於 Hinting 的需求也越來越少,在較新的作業系統上可能會忽略部份 Hinting 的 資訊或是完全關閉 Hinting。而在自由軟體的世界中,大多使用 FreeType 的 Auto-Hinting 技術來支援解析度較低的顯示裝置。
參考資料:
MingLiu
細明體 (MingLiu) 與新細明體 (PMingLiu) 是華康 (DynaLab) 設計的字型,內 建於 Microsoft 的作業系統中,使用非常廣泛。華康的字型使用了特殊的組字 方式,似乎是為了從自有的字型資料轉換到 TrueType 才會使用這樣的方法。
首先,定義一組筆劃的字符,只用來組字,不對應到任何的編碼:
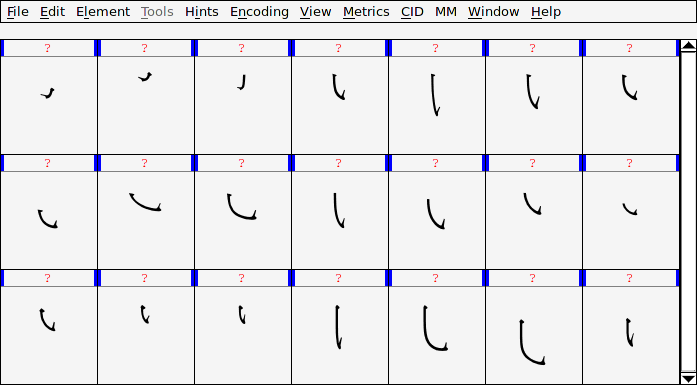
然後在每一個個別的字符中用參照的方式把筆劃匯入,這時筆劃間的相對位置是 亂的,最後再用 Hinting 的功能把筆劃移動到對的位置去:
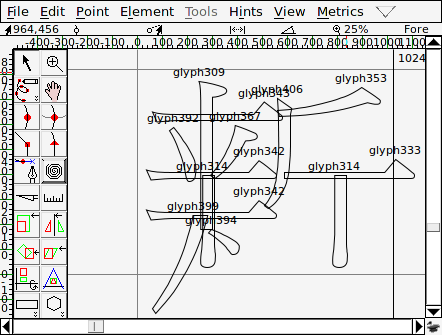
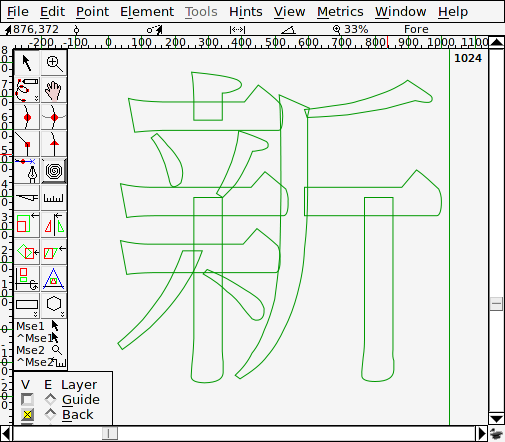
這樣濫用 Hinting 的方式,也導致如果不開啟 Hinting 就會看到破碎的字符:

為什麼說是濫用?因為只要沒有打開 Hinting 就會顯示錯誤,表示用錯地方了; 有些時候是不需要,或是沒辦法使用 Hinting 的。
參考資料:
Tricky Fonts
除了新細明體,華康還有一些字型也是使用類似的方式組字,同樣很多人使用的 標楷體就是其中之一,還有一些日本字型也是濫用 Hinting 的功能來繪製字符, 所以 FreeType 其實有內建黑名單來對付這樣的字型,遇到了就強制開啟 Hinting。一開始這個名單是用字型名稱來列表的:
static const char trick_names[TRICK_NAMES_COUNT]
[TRICK_NAMES_MAX_CHARACTERS + 1] =
{
"DFKaiSho-SB", /* dfkaisb.ttf */
"DFKaiShu",
"DFKai-SB", /* kaiu.ttf */
"HuaTianKaiTi?", /* htkt2.ttf */
"HuaTianSongTi?", /* htst3.ttf */
"MingLiU", /* mingliu.ttf & mingliu.ttc */
"PMingLiU", /* mingliu.ttc */
"MingLi43", /* mingli.ttf */
};但是這樣還不夠,因為很多 PDF 輸出軟體會把字型的名稱亂改:
% pdffonts ~/pdf31yNwCi71d.pdf
name type emb sub uni object ID
------------------------------- ----------------- --- --- --- ---------
AAAAAA+TimesNewRoman TrueType yes yes yes 9 0
AAAAAB+___ TrueType yes yes yes 16 0
AAAAAC+___ TrueType yes yes yes 17 0
AAAAAE+____ TrueType yes yes yes 18 0
AAAAAD+____ TrueType yes yes yes 19 0遇到這樣的情況就破功了,所以很多人在看 PDF 的時候會遇到字破掉的問題,我
先在信中提出可能的解法,後來發現 Suzuki Toshiya 在 2010-11-22 的時候加
入用 cvt/fpgm/prep 表格的加總檢查來比對黑名單,因為這三個表格是只要是
有使用 Hinting 的字型都會有,也不太會改變的。
static const tt_sfnt_id_rec sfnt_id[TRICK_SFNT_IDS_NUM_FACES]
[TRICK_SFNT_IDS_PER_FACE] = {
...
{ /* MingLiU 1995 */
{ 0x05bcf058, 0x000002e4 }, /* cvt */
{ 0x28233bf1, 0x000087c4 }, /* fpgm */
{ 0xa344a1ea, 0x000001e1 } /* prep */
},
{ /* MingLiU 1996- */
{ 0x05bcf058, 0x000002e4 }, /* cvt */
{ 0x28233bf1, 0x000087c4 }, /* fpgm */
{ 0xa344a1eb, 0x000001e1 } /* prep */
},
...只是原先這個方法只有在字型沒有名稱的時候才會啟用,我加了 patch 改成無條 件檢查黑名單,從此就應該不會有漏網之魚了。
參考資料:
- Re: How to read Chinese PDFs anymore with xpdf?
- [truetype] Identify the tricky fonts by cvt/fpgm/prep checksums.
- [truetype] Always check the checksum to identify tricky fonts.
- [truetype] Revert the reordering of trickyness checking.
- [truetype] Register a set of tricky fonts, NEC FA family.
Sign Extension
只是後來我在我的機器上面仍然發現某些 PDF 仍然顯示破碎字型,難道是加總 檢查也會出錯?因為牽扯到加總的問題,第一個想到的就是可能跟機器的整 數長度有關,立刻改用 32-bit 的環境測試同一個 PDF,果然就好了。但是計 算檢查碼的演算法很簡單,也沒有溢位的疑慮,那是哪裡出了問題?好在 IRC 上有大大給了提示:
kanru> hum.. checksum *: 0xa344a1eb
kanru> checksum #: 0xffffffffa344a1eb
j5g> kanru: 哈,因為 init checksum = 0xffffffff, sign extension 變
成 0xffffffffffffffff?
j5g> 然後之後都只處理後面 32bit
kanru> j5g: 不過有可能是 font 裡面是錯的
kanru> 0xffffffffa344a1eb 是直接從 font table 讀出來的
j5g> 喔,那就是 0xa344a1eb sign extended to 0xffffffffa344a1eb原來是 FreeType 在讀入字型資訊的時候,強制把 int 轉型為 uint 結果發生 sign extension 錯誤,之後比對的時候就跟著錯了。送了 patch 之後,應該天 下太平了吧?
參考資料:
PDF correctness
有人問說:那為什麼不乾脆隨時打開 Hinting 就好?據我所知目前的自由 PDF Viewer 都是預設關閉 Hinting 的,除了上述的理由外,我猜大概是因為 Hinting 有可能大幅度的改變一個字符的寬度,如下圖:

可以發現三種顯示方式的寬度都不一樣,而 PDF 是一種接近印刷品質的檔案格
式,有可能在輸出 PDF 的時候已經丟失動態改變寬度的能力,kern 的修正也已
經沒辦法修改,這時候如過還讓 Hinting 去改變字符的寬度的話,很有可能得到
不理想的結果。不過以上只是我的猜想,還沒有找各 PDF Viewer 的作者證實。
至於封閉的商業 PDF Viewer 又是怎麼做的就更不得而知了。
結論:快升級到最新的 FreeType 吧!如果還有遇到顯示錯誤的 PDF 可以寄給 我,如果以上筆記有疏漏錯誤的地方歡迎指正 😋