GNU software often comes with a large set of documents in texinfo format, which can be typesetted to a real book. For example the Gnus Manual has over 500 pages, full of fun and humor. Having a mobi version on my Kindle would be quite handy.
閱讀全文 Convert Texinfo to MOBI月份: 2010 年 11 月
Understanding UUID
通用唯一識別碼 (Universally Unique IDentifier, UUID) 或是全域唯一識別
碼 (Globally Unique IDentifier, GUID) 是一個 128 bits 的整數,並保證其
在時間與空間的分佈都是獨一無二的。UUID 由開放軟體基金會(OSF) 標準化後
用在他們的 DCE 系統上,後來在微軟的 COM 系統上發揚光大。除此之外在許多
地方也都可以看到 UUID 的身影,如 Linux 上的分割表/區塊裝置就是以 UUID
來標示,或是RSS 的 <guid> 標籤也可以使用 UUID,實際上 UUID 是標準的
URN 表示法之一,你可以在任何需要標示單一物件的地方使用 UUID。
UUID 的文字形式為一個 8-4-4-4-12 的十六進位表示,共有 16 個 bytes,有
人說使用 UUID 不方便人類辨識,但了解 UUID 的組成後你還是可以從這個表示
法看出一些端倪來。本文參考的是 IETF 版本的 RFC4122。
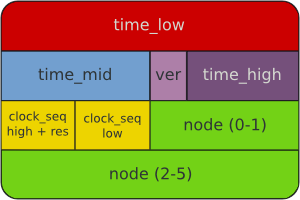
UUID 共有四個版本,第 13 個字元的位置就是表示版本號。第一種是以時間和網
路卡號組成,時間是以一百奈秒為單位,網路卡號理論上是不會重複的,再加上clock_seq 這個每次開機重設一次的亂數欄位,就算時間回朔了也不會重複,
代號是 1。第二種和第四種是以命名空間加上一個 hash 組成的,分別可以使
用MD5 或是 SHA1 演算法,算出來後就填到空位中,代號是 3 跟 5。第三種
是全亂數組成,代號是 4。
因此我們可以在不同的情境選用不同的 UUID,也可以從 UUID 看出版本跟時間等
資訊,如 4ef17586-f187-11df-8xxx-xxxxxxxxxxxx 看到第三個區塊是11df 就可以知道是最近產生的以時間卡號為基礎的 UUID,時間1dff1874ef17586 解出來就是 2010-11-16 13:42:09.173031.0 UTC。而7c0fdbe4-1b09-4278-9fc9-5f0c6a1f2ae2 就是純亂數的 UUID,沒有任何
意義。
uuid-el
在轉換 Blog 到 ikiwiki 的時候,為了要整合 Disqus 系統,每篇都需要一個唯
一的識別碼,這樣 Disqus 就只認 UUID 而不是網址,將來網址變了也可以對得
上,而此 ID 也可以用在 RSS, ATOM 上面。研究了 RFC 4122 後,用 elisp 寫
了產生 UUID 的工具,uuid-el,使用只需要:
(require 'uuid)
;; Generate UUIDv1
(uuid-1)
;; Generate UUIDv4
(uuid-4)
;; Generate UUIDv3, v5
(uuid-3 uuid-ns-url "http://example.com")
(uuid-4 uuid-ns-url "http://example.com")
搭配以下 snippet 就可以快速展開需要的 metadata:
# -*- mode: snippet -*-
# name: meta
# key: meta
# --
\[[!meta title="$1"]]
\[[!meta guid="${1:$(uuid-urn (uuid-5 uuid-ns-kanru text))}"]]
\[[!meta date="${2:`(current-time-string)`}"]]
$0
最後補上影片:
下一集:用 ffmpeg 製作桌面錄影
Blog Redesigned
最近又把 Blog 整頓了一番,目標是改用靜態網頁。使用靜態網頁搭配一些網頁
樣板程式不禁讓人想起最初使用 MT 來寫 Blog 的時候,不同的是現在有像
Disqus 或是 IntenseDebate 這樣的動態留言服務,讓網頁可以完全
的只提供靜態內容,不用多一個 cgi 程式來提供留言功能,這隱然成為最近流行
的網頁設計方法之一。
轉換的過程中學到一些新東西,紀錄於此。
網頁編譯器
現在網頁是用
產生的,它是大師 Joey Hess 的作品,大師稱它是一個
wiki compiler,
可以透過各種規則把網頁的原始碼 (可能是 markdown 的格式) 轉成 HTML 網頁。
因為強大的 inline 規則以及各式各樣的外掛程式,也有許多人把 ikiwiki 當作
Blog 的平台。
轉換的過程其實滿順利的,因為舊的 Blog 都是以 Markdown 寫成,換到
ikiwiki 的 Markdown 引擎只需要一點點修改。要感謝 WordPress 可以把資料
庫匯出成 XML 格式,轉換只需要簡單的 XSLT 就完成了,我用的
XSL 是參考這裡修改,去掉
Comment 以及更新 meta的格式而成。
改用文字編輯器來寫 Blog 後,會習慣在 72 行的地方換行,但是在瀏覽器中只
要換行就會多一個空白,以前寫網頁的時候遇到中文都要小心的換行才不會讓不
該空白的地方出現空白,也不能打開 Emacs 的 auto-fill 模式。拜 ikiwiki
強大的外掛程式架構以及 Perl 的 Unicode 正規表示式支援,寫個
外掛把不該空白的地方黏起來只要幾分鐘
時間!而 Blog 原始碼則維持容易閱讀的格式。
HTML5
既然都換了 Blog 系統,也打算換新的版面,乾脆就升級到網頁標準的新世代
HTML5。在收集 HTML5 相關資訊時發現了 HTML5 Boilerplate 這個網頁樣
板計畫,包含了許多目前 HTML5 的 Best Practice,基於這個樣板設計網頁讓
你馬上就 HTML5 Ready ☺
我認為 HTML5 最有趣的一點是帶有語意的新標籤,如 <article>,<section> 等等,搭配新的大綱演算法可以自動產生大綱,運用得當
的話,對於機器或是身體不便的人都能更方便的取得資訊。
ikiwiki 原本就有支援實驗性的 HTML5 模式,但是預設的樣板不是很完美,例如
多層嵌套的 <section> 與 <nav> 和 <article>,都會產生多餘的大綱節
點,若只是需要群組與排版功能的話,最好還是使用 <div> 就好。如我現在
用的 template 長得就像這樣:
<article>
<header>
<h1>TITLE</h1>
<time>TIME</time>
</header>
<div class="content">
CONTENT
</div>
<footer></footer>
</article>
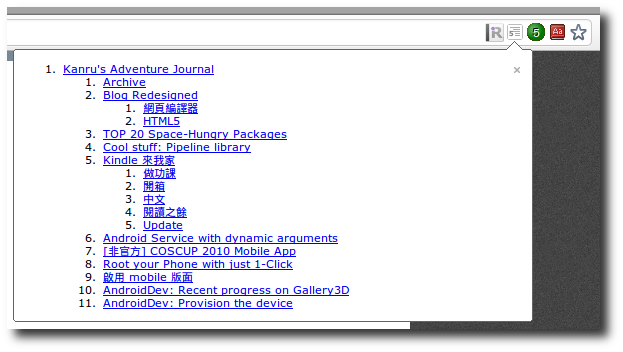
這裡推薦使用 HTML 5 Outliner 來檢查網頁的大綱,或是用專門的
Chrome 擴展,如果網頁設計無誤,應該會看到如下乾淨的大綱:
Web Fonts
使用網路字體可以讓網頁在不同的作業系統、不同的瀏覽器上看起來都是一樣的,
現在有很多提供網路字體的服務,像是 Google 也推出
Google Font Directory,甚至 Fonts.com 還有免費的中文網路字體,
參考 Type Is Beautiful 的測試頁,速度還不錯呢。
我現在用的是從 Font Squirrel 下載的自由字體,這個網站上不但有大
量的自由字體可以挑選,還有預先整理好的 @font-face Kits 可以直接使用,
或是用 @font-face Generator 產生最佳化的網路字體。
結語
這篇是心得筆記的性質,因為如果不紀錄一下可能很快就忘了…有許多細節都省
略過去,若是要深入探討則每個主題都可以發展成長篇大論,需要更詳細資料的
網友可以參考引用的連結。
一些眉眉角角的東西希望之後有機會可以再單獨拿出來分享囉 ☻
TOP 20 Space-Hungry Packages
Arch Linux 與 Debian 皆可以在安裝的時候選擇最小安裝,究竟哪一個
Distribution 在使用一段時間之後最佔空間呢? 剛安裝完的時候似乎是 Arch
比較小一點,但是因為 Debian 套件切的比較細,所以最後可能是 Debian 會比
較小。
當初在試用 Arch 的時候寫了小程式來畫出前 20 個最佔空間的套件,並依此來
瘦身,結果如下:
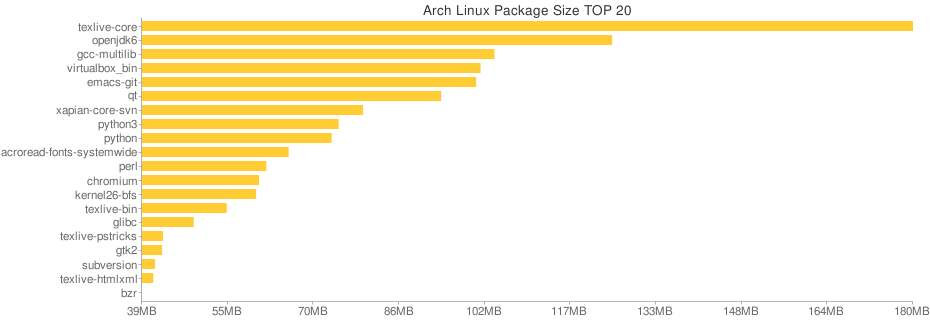
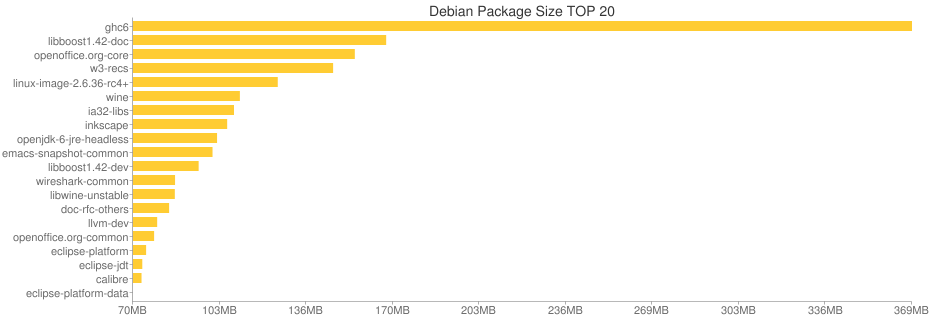
兩邊因為安裝的套件種類不同因此無從比較,Arch 的 TeXLive 因為沒有切所以
會比 Debian 上較大一點,Debian 上的 ghc6 則是為了測試 xmonad 裝的,
Haskell 本身做出來的執行檔就頗大,ghc6 需要 369MB 實在不意外…
底下是製作圖片的程式,實際上是用 Google Chart API 畫的:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from pygooglechart import StackedHorizontalBarChart, Axis
from subprocess import *
TITLE="Debian Package Size TOP 20"
PKGSIZE_PROG="./dpkgsize"
OUTPUT="debian-top20pkg.png"
chart = StackedHorizontalBarChart(930, 320)
chart.set_bar_width(10)
chart.set_title(TITLE)
size_data = []
name_data = []
for ln in Popen([PKGSIZE_PROG], stdout=PIPE).stdout:
size, name = ln.split()
size_data.append(int(size))
name_data.append(name)
chart.add_data(size_data[:20])
max_size = size_data[20]
min_size = size_data[0]
label = map(lambda x: str(x / 1024)+"MB",
xrange(min_size, max_size, (max_size-min_size)/10))
label.reverse()
rev_name_data = name_data[:20]
rev_name_data.reverse()
chart.set_axis_labels(Axis.LEFT, rev_name_data)
chart.set_axis_labels(Axis.BOTTOM, label)
print(chart.get_url())
chart.download(OUTPUT)
把 PKGSIZE_PROG 代換成自己 Distro 的就可以了:
Debian:
#!/bin/sh
dpkg-query -W -f='${Installed-Size} ${Package}\n'|sort -nr
Arch:
#!/bin/sh
pacman -Qi|awk '/^Installed Size/{print int($4), name} /^Name/{name=$3}'|sort -nr
Cool stuff: Pipeline library
如何在 C 程式中方便使用 pipeline 呢?
Unix pipeline 之父說 Unix 程式的哲學就是「只做一件事,並把它做好」:
“This is the Unix philosophy: Write programs that do one thing and do
it well. Write programs to work together. Write programs to handle
text streams, because that is a universal interface.”
― Doug McIlroy, the inventor of Unix pipes
平常有在使用 shell 的朋友想必對 | 這個符號不陌生,他可以把多個指令頭尾相接,各展所長,讓我們可以把各程式的力量組合起來成一個強大的 pipeline。
在 shell script 中可以輕鬆做到的事在程式中就不一定這麼簡單了,在 perl 中可以直接用 open 打開程式作為輸出入裝置,在 python 中有 subprocess 模組的 Popen 可以用,但如果只寫 C 呢?你可以用 pipe2 配合 fork 與 exec—沒錯,想起 Unix Programming 課本了嗎 😉
用 C 寫這樣的程式既麻煩又容易寫錯,Colin Watson 寫到他在維護 man-db 的時候為此寫了專用的 pipeline library,現在決定要把 libpipeline 獨立以 GPLv3 釋出。
使用 libpipeline 如果我們要產生像
apt-get moo|cowsay -n
這樣的 pipeline,可以這樣寫:
pipeline *p;
int status;
p = pipeline_new ();
pipeline_command_args (p, "apt-get", "moo", NULL);
pipeline_command_args (p, "cowsay", "-n", NULL);
pipeline_start (p);
status = pipeline_wait (p);
pipeline_free (p);
還可以在 pipeline 中間安插 “built-in” 命令:
command *inproc = command_new_function ("in-process", &func, NULL, NULL);
pipeline_command (p, inproc);
有趣嗎?更詳細的說明可以參考 libpipeline(3) 說明文件。