
回顧用 Rust 重寫新酷音的經驗
libchewing 0.8.0 將是新酷音的重大里程碑。酷音原本是 XCIN 的一個模組,新酷音團隊在 2002 年把模組獨立出來變成一個共有函式庫 (shared library) 維護至今。從 2021 年開始我就斷斷續續的用 Rust 重寫 libchewing,現在終於要預設啟用 Rust 重寫的版本了!我現在一邊為釋出做最後的準備工作,一邊寫個文章紀錄一下整個重寫的經驗,順便最後測試實際使用的情境。這篇文章將會以紀錄發生了什麼事為主,不會解釋太多技術細節,如果有想要深入了解的部份,歡迎留言讓我知道。
2017 年的第一次嘗試
應該是在 2017 年八月的時候,那個時候剛剛接觸 Rust 沒有多久,就想著可以用新酷音練練功,試著把使用者詞庫的模組 (userphrase) 改用 Rust 的 HashMap 改寫。那個時候新酷音的建置環境還是用 autotools 以及 libtool,重寫的結果算是證明了可以把 C 跟 Rust 放在同一個程式碼庫內一起編譯使用。練習的結果在 COSCUP 給了一個經驗分享 (COSCUP 2017 – Porting C Library to Rust, 以 libchewing 為例)。
2021 年底重新開始的契機
2021 年底的時候開始玩流行的寫程式解謎遊戲 Advent of Code,依照我的慣例是用 Rust 寫 (adventofcode2021)。寫著寫著不禁想,同樣是透過寫程式娛樂,我不如把時間花在寫一些對其他人有幫助的程式。同樣是 2021 年接觸了 QMK 與 ZMK,覺得好像可以把寫鍵盤 firmware 的經驗應用在酷音的鍵盤對應表上,於是又開始想要怎麼把新酷音用 Rust 改寫。
這時候只是開始隨便寫寫,驗證自己心裡所想的架構可以運作,並重新閱讀 libchewing 的程式碼,重拾對程式碼的了解。
2022 年黃金週確立基礎架構
4/29 為期一週的黃金週假期開始,在 Matrix 上面開了新的聊天室,把聊天室的連結加到 README 之後就開始先加入 CMake 的 FindRust 模組,讓 libchewing 可以連結 Rust 的程式碼,然後就陸續把許氏鍵盤、表準鍵盤、倚天26、大千鍵盤等等鍵盤模組實做出來並且替換 C 的內部 API,採取的是從最末端的程式碼一步一步的取代更大的 C 模組。(開發紀錄)
此時要感謝 czchen 幫新酷音加了非常多的測試,我可以直接用原本的測試程式來確保大致功能是對的。要不是有這些測試程式,我的進度一定會要慢上好幾倍。而且這些測試很多都是整合測試 (integration test),讓我可以不必理會原本 C 是怎麼實做的,只需要依照 API 界面實做即可跟原本的程式合在一起測試。
等所有的注音輸入模組都寫的差不多之後,我開始寫字典的讀取查找模組,這是酷音裡面重要又有一定複雜度的模組,但是又相對的獨立沒有其他的相依性,所以是很好的重構目標。首先我實做了一個新的 Trie 檔案格式以及字典建構工具,然後又寫了 SQLite 為底的使用者字典格式。此時很多時候都是在逆向工程原本字典模組 (tree.c) 的一些規則,像是排序的順序、詞頻的調整等等。原本的 tree.c 用的是記憶體映射 (mmap) 的方式把字典檔案直接當作記憶體位置操作,直接回傳一個唯讀的記憶體指標,我在重構的時候就直接分配新的記憶體然後不釋放,等到測試都過了之後再慢慢的修 valgrind 報的記憶體洩漏錯誤。(開發紀錄)
此時我已經把新酷音內最沒有其他相依的兩大模組換成 Rust 了,我也漸漸有信心好像可以完成這個「小專案」。有了字典模組之後,接下來就是需要使用字典模組的注音分詞的酷音模組了,這邊的演算法我一直不是很有信心,加上工作變忙於是就慢慢的摸索,直到 12 月又到了 Advent of Code 的時間才又開始有精力開發。把酷音的演算法移植到 Rust 之後很令人驚訝的是大部份的測試都過了,既開心有不錯的進展,卻又有點擔心已有的測試在分詞模組的覆蓋率有點不足。我要感謝聰明又可愛的老婆不厭其煩的跟我討論我最沒有信心的演算法。(開發紀錄)
2023 年合併到主線開發
把詞庫跟分詞模組都重構完之後,就有機會把原本兩個模組之間黏合用的 C API 拿掉了。兩個模組之間用新設計的 Rust API 組合之後,整個新酷音除了使用者的輸入輸出的部份都已經是 Rust。我開始整理 commit history 然後把結果提交為 pull request,並分享未來的開發計畫。此時也已經換成用 Corrosion-rs 這個優秀的 CMake 專案來編譯 libchewing。採用的是 Rust staticlib + dummy C file + version script 的方式來產生共用函式庫。
提交 pull request 之後,感謝眾多的 reviewer 給予建議,我也開了許多 ticket 供想要參與的人可以幫忙或是尋求指導。Pull request 裡面的參考架構仍然接近現在所使用的架構:
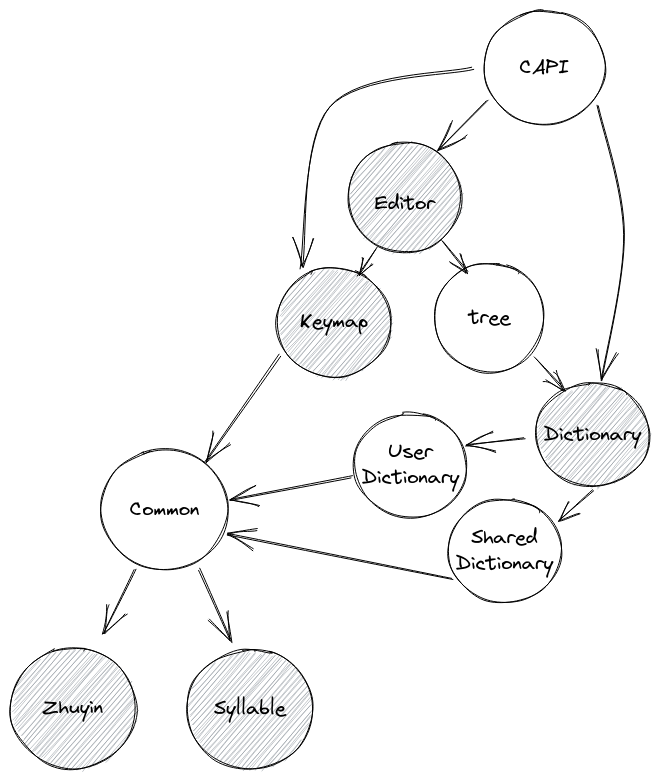
接下來開始設計 Editor (input/output) 模組,這個模組跟其他模組不一樣的地方是它有著非常多的 API 以及內部資料狀態 (state),沒有辦法像其他模組一樣漸進式的處理。原本 libchewing 的 chewingio.c 與 chewingutil.c 等,總共有約 119 個 API,全部都是透過操作內部狀態以及使用詞庫和分詞模組來實做新酷音的主要功能,這些 API 全部都共用同一組狀態,存在 ChewingContext 裡面,所以沒辦法單單只把一些功能搬到 Rust。
後來因為注意到在跑 test 的時候,Rust 的版本比純 C 的版本要慢上一個數量級,所以花了些時間用 samply 來了解問題在哪裡〔很多時間是花在原本較沒效率的 syllable 設計,後來把內裝改成用 u16 之後改善不少〕。我從 7 月開始除了偶爾構思一下暫存編輯區 (preedit text)、候選字清單 (candidate window)、編輯區邏輯 (editor state machine) 的架構之外,都花時間在最佳化 Trie 字典的效能,逃避不想面對的複雜重構。
11 月參考 hoverbear 的 blog 設計了新的 state machine 架構,花了些時間把 C 的 119 個公開 API 用 Rust 重寫,把 API 跟 Editor 跟字典模組直接整合起來,得到一個只有用到 Rust 程式碼但是測試壞掉大半的狀態。接下來就是一個一個修 test-bopomofo.c 的錯誤。我幾乎都是把原本的 C 實做當作黑盒子做 TDD,因為如果依照原本的邏輯實做,會受到原本架構的影響。一旦有了可用的 state machine 架構之後,我就以還算穩定的速度在年底前就把所有的測試都通過了。(開發紀錄)
2024 開始穩固基礎
等到測試都通過之後改用 genkeystroke 測試一般的使用情境,此時會發現雖然有很多小地方都還沒有處理〔例如選詞結果不會清除〕,已經可以通過所有的測試以及一般的使用情境都沒有問題。這證實我之前的猜測,現有的測試只能帶我到大約 80% 的地方,剩下的 20% 需要靠其他的方法測試才行。
所有的測試都通過之後,表示 Rust 版本的酷音已經可以用在基本的使用情境了,也可以編譯出只有使用 Rust 的 libchewing.so 共用函式庫。接下來需要更廣泛的測試,首先在 CI 上面在所有平台同時測試 C 跟 Rust 版本,以免有任何的退步。一月底的時候釋出 0.6.0 為 2016 年以來的第一個維護版同時也是第一個 alpha 版的 Rust rewrite 版。 (開發紀錄)
0.6.0 釋出之後就開始準備可以日常使用、抓蟲的 0.7.0 版,根據之前定義的路線圖這個版本有以下重點項目:
- 可以自動的搬遷使用者字典到新的格式
- 穩定性優先,盡量不可以有嚴重錯誤或是毀壞使用者資料
- 減少不必要的相依項目
穩定性的部份,我從一開始就希望可以用 fuzzing 的方式幫我找到更多的 bug,最後我用 clang + afl.rs 的方式編譯出有 instrument 的執行檔,讓 AFL++ 可以更有效率的執行。
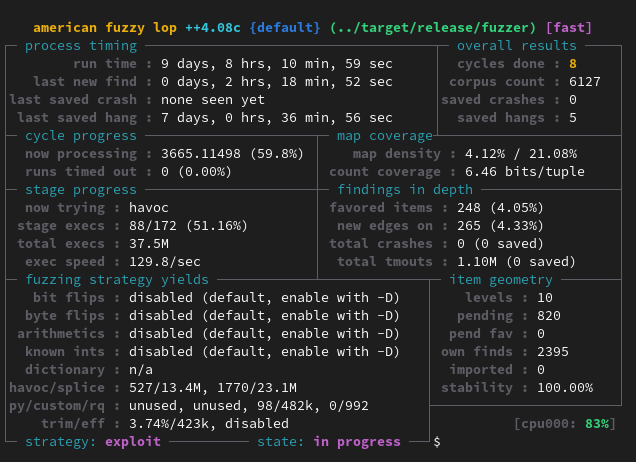
用了 AFL++ 之後很快就找到許多原本的測試沒有找到的問題,大多都是因為原本的 state machine 沒有阻擋把游標移動到超出編輯區的頭尾,或是選擇鍵超出頁面範圍。原本這些問題在 C 的版本會非常難偵測,但是因為 Rust 有邊界測試以及數值溢位的偵測,這些問題都可以很簡單的發現並修復。持續的跑 fuzzer 好幾天都沒有發現新的問題之後,我更有信心日常使用使用者不會遇到程式嚴重錯誤的問題,最多只是程式的輸出結果很奇怪。(開發紀錄)
※ 一個用 fuzzer 找 bug 的小技巧,我在日常測試的時候出現一個問題,就是編輯區的詞有時候會消失,但是不知道要怎麼重現,我就在 fuzzer 裡面特別加了一個檢查,很快 fuzzer 就找到好幾個 testcase,原來是我根本就沒有處理選詞之後的重新整理,沒想到這樣也可以用到現在。
在準備 0.7.0 正式 release 之前,我決定替換字典的實做。一開始在設計架構的時候預留了可以有多種不同字典格式的設計,也實際實做了 SQLite, Trie, CDB 三種不同的字典格式,其中 SQLite 是可以更新的,CDB 雖然是唯讀的格式,可是利用一個技巧把需要更新的內容先快取在記憶體內,然後定期的覆蓋硬碟上的字典檔,也可以達到更新的效果。後來在做效能測試的時候發現建立 Trie 沒有比寫新的 CDB 檔案更花時間,所以如果用一樣的技巧就可以把 Trie 格式當作可更新的使用者字典來用,於是就有想法把系統字典與使用者字典全部統一成一個格式,這樣可以讓整體的相依更少。
最後,2024 年的黃金週現在準備釋出 0.8.0,把 Rust 重寫的版本變成預設選項。把 chewing-cli 開發成一個通用工具程式,包含原本用來建立系統辭典的 init-database 程式,並加上新的 info 與 dump 兩個命令,可以用來檢視字典的內容。這個版本還用了一個 K Shortest Path 演算法 (Yen’s Algorithm) 來加強搜尋候選斷詞清單的最差時間複雜度。(開發紀錄)
最初採用卻沒有留下的設計
Tracing. 原本用了 Tokio 的 tracing crate,可以很方便的幫 function 加上 tracing log,對於實做 Editor 的 state machine 幫助極大,可是後來的 log 需求比較簡單,於是就改回相依項目比較少的 log crate。
RIFF. 一開始設計的新 Trie 字典格式仿照了 WebP 的格式標準,用了 RIFF 容器格式作為可擴充的檔案格式基礎,把 index 與 data 封裝在同一個檔案內,後來在重新設計的時候因為需要更有彈性的儲存詞彙資料而改用 ASN.1 描述檔案格式,並用 DER 做為檔案的實做格式,就沒有用 RIFF 了。
CRC32. 原本的 Trie 字典格式裡面用了許多自訂的 TLV 封包,在做 fuzzing 的時候發現有很多邊界測試需要做,於是就在 index 跟 data 資料的最後面加上 CRC32 的檢查碼,然後就在程式裡面假設如果檢查碼通過的話就當作資料都是正確的,省掉許多的額外邊界測試,算是有點偷懶。後來因為 TLV 太麻煩不想處理,直接用標準的 TLV 格式,也就是 ASN.1 的 DER 格式,也就沒有一定要用 CRC32 檢查碼了。之後可能會加回來讓檔案更牢不可破。
CDB. 一開始設計來取代 uhash.dat 格式的,用了 DJB 的 CDB 格式,跟原本的 uhash 一樣把字典當作 key/value 存。如同前面提到的,因為把字典格式統一為 Trie 與 TrieBuf 之後就沒有用 CDB 了。
SQLite. 最新的 libchewing 是用 sqlite3 當作使用者字典的格式,好處是有支援多行程,ACID,然後其他的工具或是使用者可以直接操作 sqlite3 檔案。最一開始改寫的時候重新設計了 schema 讓 sqlite 更有效率,並且支援大於 10 個字元的詞彙詞。後來因為想要減少額外的相依項,重新設計讓 TrieBuf 格式也可以更新之後,就打算移除 SQLite 格式了,目前因為需要可以從舊有格式轉移,這部份的程式碼還留著。
Symbol versioning. 一開始在實做只用 Rust 編譯整個 libchewing 的時候,採用的是用 cmake 去呼叫 linker 來產生最後的 shared library,因為這樣可以更容易的控制哪一些 symbol 是 public 的,這時候我用了 version script 來控制 ELF library 的 symbol version,後來因為想用 cargo + rustc 直接產生 shared library,而 rustc 又不支援用 version script,所以就暫時放棄了 symbol version 的想法。
感謝
首先感謝我自己在 2004 年寫的 testchewing 與 genkeystroke 兩個小程式,可以在沒有 GUI 或是任何 IM wrapper 的情況下直接測試 libchewing,同時 genkeystroke 可以用來產生測資,而 testchewing 可以用來執行 genkeystroke 產生的測資。酷音的很多測試用的也是 testchewing 所使用的檔案格式。這兩個程式仍然是我測試 libchewing 時不可或缺的工具。
接下來要感謝 czchen,他替 libchewing 加了 cmake 的支援,以及大量的測試。若是沒有這兩者,我根本無法想像開始用 Rust 改寫的計畫。我的改寫基本上都是 TDD (Test Driven),全部都歸功於這些測試。感謝我一開始的決定先把 GitHub Actions 的 CI 設定好同時跑 C 跟 Rust 的整合測試以及計算覆蓋率,我在重構的時候以及有人貢獻的時候都可以有明確的品質指標。目前整個程式庫大約有 88% 的測試覆蓋率。
感謝 Rust Taiwan 的 wusyong 與 weihanglo 幫忙 review 最初的 pull request,以及其他夥伴在 Matrix/Telegram 上提供的各種建議。
感謝 rano 開發直接使用 chewing-rs Rust API 的實驗性 IM chewingwl 並在 Matrix 上面給予回饋。
最後要感謝 yan12125 與 wengxt 幫忙實際測試 libchewing 0.8.0 並回報問題,jserv 幫忙更新 README 裡面新酷音的歷史以及現狀。▞
※ 封面照片是 2022 年黃金週去東京野鳥園玩的時候拍的螃蟹