
網路上有一個笑話:有在寫部落格的工程師,都至少有寫過一次自己的靜態網頁編譯軟體,而且比起真正寫部落格,會花更多時間在重構這個軟體或是調整模板。回頭看看我自己網站上面的文章,自從發出 Blog Redesigned 這篇文章之後,文章數量從每年幾篇,直接掉到每三年一篇。為什麼呢?
閱讀全文 回頭用 WordPress 寫部落格標籤: zh-TW

桔梗種植的第二年更新
桔梗的葉子在冬天會枯萎,但是地下長的像人蔘的根部則是會進入休眠狀態。等到春天白天氣溫約 17 度的時候,就會重新萌發出新芽。
閱讀全文 桔梗種植的第二年更新
桔梗花的種植與照顧
桔梗(學名:Platycodon grandiflorus),别名包袱花、鈴鐺花,擁有可愛的小花,帶有獨特的紙張質地和可見的花脈。我所在地區(日本東京)的常見品種有紫色和白色的花朵。這種植物的一個顯著特徵是它的花苞在完全打開之前像氣球一樣膨脹。
閱讀全文 桔梗花的種植與照顧
JSON Web Tokens
- 什麼是 JSON Web Tokens ?
- JSON Web Tokens 要怎麼用?
- 使用 JSON Web Tokens 的好處
- 傳統的 Session
- JSON Web Token 的潛在問題
- 把 JWT 或是 session ID 存在 cookie 的好處
- 結論
- 參考文獻
JSON Web Tokens 是什麼?它真的可以用來取代傳統的 session cookies 嗎? 本篇為研究 JWT 時所做的筆記。
閱讀全文 JSON Web TokensSimpler way to load CSS asynchronously
在 Smashing Newsletter 看到的,只要 <link> 標籤就可以簡單把 CSS 變成非同步讀取:
<link rel="stylesheet" href="/path/to/my.css"
media="print" onload="this.media='all'">有用過 Google PageSpeed Insight 分析網站的,應該都有看過如下的結果:

原因是因為瀏覽器在處理 CSS 與 JavaScript 檔案的時候會阻擋其他資源的載入。解決的 方法裡,JavaScript 類型的資源可以標示 defer 或是 async 屬性讓瀏覽器知道我們 希望可以非同步的載入執行此 JavaScript 檔案,可惜 CSS 並沒有類似的屬性可以使用。
一般處理 CSS 的載入有兩個策略:
- 盡量把最重要的樣式內嵌(inline)在 HTML 內,
- 用 JavaScript 動態的插入
<link>標籤。
策略 1. 應該不難理解,因為都已經要下載 HTML 了,不如把少部份最重要的樣式直接也寫 在裡面,可以省下一次網路請求。策略 2. 則是把其他剩餘的樣式集中在一起,用 JavaScript 在網頁讀取完畢後再動態的插入 <link> 標籤讓瀏覽器套用。LoadCSS 似乎是個常用的 library 但是我沒有用過,因為我不喜歡這種需要很多 JavaScript 的解 法。
這次看到的這個方法非常簡單,原本的 CSS 標籤如下:
<link rel="stylesheet" href="/path/to/my.css">只要再加上 media="print" 以及 onload="this.media='all'" 就可以讓瀏覽器非同步載入 CSS 了!
原理是,瀏覽器在遇到非使用中的 media 時,只會下載但是不會套用樣式,所以設定 media 為 print 可以避免套用 CSS 的時候延遲其他的資源的載入,而 onload 的部 份則是在等到其他資源都載入完畢後,才把 media 切回 all 或是 screen 讓瀏覽器 套用樣式。雖然還是需要一點點 CSS,整體看起來清爽許多,也不需要額外的 library!
如果需要支援沒有開啟 JavaScript 的瀏覽器,記得加上 fallback:
<noscript><link rel="stylesheet" href="/path/to/my.css"></noscript>完整的範例如下:
<link rel="stylesheet" href="/path/to/my.css"
media="print" onload="this.media='all'">
<noscript><link rel="stylesheet" href="/path/to/my.css"></noscript>我迫不及待的立刻試用了? ∎
CSS Text 3: Segment Break Transformation Rules
去年年底,我利用閒暇時間1修好了 Firefox 的 Segment Break Transformation Rules 實做(Bug 1081858)。從 Firefox 52 開始,HTML 裡面中文與中文之間的換行,瀏覽器排版時不會顯示為空白。
閱讀全文 CSS Text 3: Segment Break Transformation RulesSource Han Sans & FreeType
前陣子 Adobe 和 Google 聯手各自用不同的名字釋出了一款新的中文黑體字形,Source Han Sans 思源黑體,也叫做 Noto Sans (反腐字?)。開心試用之後,把系統字形都換過來,也開始想要怎麼樣才可以達到最佳的顯示效果,尤其是 Adobe 和 Google 曾經給 FreeType 貢獻了 CFF 字形引擎的改進,思源黑體也是以 CFF 技術設計,終於可以試試看中文的效果怎麼樣了啊!
我這邊使用 FreeType 的工具程式 ftview 來測試不同參數設定下的顯示效果,同時也附上相對應的 FontConfig 設定。可以發現不同設定下的顯示差距還蠻大的:
Auto-hinter, hintfull, grayscale anti-alias
首先是使用 FreeType 的 autohint, hintfull 其他用預設值,這應該是滿多人使用的設定,可以看到 autohinter 有很強烈的瘦身效果,把 Normal 的字變成幾乎是 Light 了。

Auto-hinter, hintslight, grayscale anti-alias
再來是使用 hintslight,許多人用以取得類似 Mac 上面的渲染效果,卻不知道 hintslight 會自動使用 autohint,這張的效果和上面類似但是略為粗了一點。思源黑體使用 hintslight 的缺點是 Normal 變細,導致和 Bold 的粗細相差太多。

Auto-hinter, hintslight, RGB LCD subpixel AA
這張的效果和上面一樣,只是啟用了 subpixel AA 所以在螢幕是 RGB 排列的 LCD 的時候會有比較銳利的感覺。

Adobe CFF native hinter, hintfull, grayscale anti-alias
這張則是使用 Adobe 去年貢獻的 CFF native hinting 引擎,這個引擎的特性是在小字的時候不但不會把字變細,反而還會加深筆劃讓字形看起來更清楚,於是 Normal 變回原本得粗細。

Adobe CFF native hinter, hintfull, RGB LCD subpixel AA
同上,只是啟用 subpixel AA 讓字形在 LCD 螢幕上看起來更銳利。

最後因為我選擇的設定是 TTF 字形使用 autohint + hintslight,CFF 字形則是使用 native hinter,因為雖然很多 TTF 字形有人工去 hint,可是一般來說 autohint + hintslight 比較可以保留細節,也不比人工 hint 差,而 CFF 字形因為有 Adobe 的加持,所以使用 native hinter 可以得到更好的效果。
<match target="font">
<edit name="rgba" mode="assign">
<const>rgb</const>
</edit>
<edit name="hinting" mode="assign">
<bool>true</bool>
</edit>
<edit name="lcdfilter" mode="assign">
<const>lcddefault</const>
</edit>
<edit name="hintstyle" mode="assign">
<const>hintslight</const>
</edit>
</match>
<match target="font">
<test name="fontformat"><string>CFF</string></test>
<edit name="hintstyle" mode="assign">
<const>hintfull</const>
</edit>
</match>
https://github.com/kanru/rcfiles/blob/fonts.conf
這是我目前的設定,至於你喜歡什麼樣的效果,可以再實驗看看各種不同的參數囉 ?
GCIN in Debian is seeking co-maintainer
尋找 GCIN co-maintainer
HIME 的事件鬧的沸沸揚揚,一切的起因之一就是有人認為 HIME 會取代 Debian
裡面的 GCIN,這是什麼狀況呢?因為在 Debian 裡面把 GCIN 棄養 (orphan)
的就是我,似乎也有必要說明一下。以下提到 GCIN 都是指 Debian 裡面的 GCIN。
最早的 GCIN 維護者是 caleb,後來他因為不再使用 Debian 所以開始找其他人
幫忙維護,而我成為 Debian Developer 的初衷就是要幫助本地的使用者有習慣
好用的套件可以用,所以就接下了這個位子。當時我也有使用 GCIN 所以就算劉
老大 (eliu) 每兩三天就有新版本我也還可以跟上,只是沒有辦法把套件整理的
乾淨點,後來不用 GCIN 了,套件的更新就漸漸脫節,因為有 Luna Archiver
的存在也讓我有偷懶的藉口,最後發現花在這個套件的時間與 Debian 的
Popcon 統計不成比例,就決定把套件給棄養了。
Debian 對於被棄養的套件的處理方式是,如果沒有出什麼大問題就會由 QA
team 來管理,但是如果有人提出 RM: RoQA 的要求,因為使用者 (Popcon) 少
且無人管理,就有可能被移出 Debian,但無正當理由甚少有直接使用新專案取
代舊專案的狀況,因此 Debian 要使用 HIME 取代 GCIN 純粹是誤解而已。
後來想想也不能把 GCIN 就這樣晾著,所以我決定要再出點力,把 GCIN 納入
Debian IME Packaging Team 的管理,並誠徵對維護 GCIN 套件有興趣的人一起
來 co-maintain,讓 GCIN 的使用者可以直接用到最新、高品質的 GCIN 套件。
有興趣的人請與我聯絡,寄信到 koster@debian.org 或是
630484@bugs.debian.org 都可以。
Not Again, MingLiu!
長話短說,從 FreeType 2.4.4 (2010-11-28 release) 開始,只要編譯的時候有啟用 BCI (Byte Code Interpreter) ,新細明體就不應該會破掉了,只是因為一些原因 (下面詳述),一直到 2.4.5 (2011-06-24 release) 才算是完全解決。
這個問題牽扯到許多有趣知識,所以我決定作個筆記以免以後忘掉。
TrueType
首先是一些名詞解釋,TrueType 是常見的字型 (font) 格式,由 Apple 發展,後來被 Microsoft 採用並發揚光大;雖然沒有經過任何國際組織的標準化,在當時儼然已經成為業界標準 (de facto standard)。
TrueType 使用的檔案格式又稱為 sfnt 格式,由許多不同的表格 (table) 組成,每個表格由四個字的標籤 (tag) 表示,其中我們最關心的是 glyf 這個表格,因為所有的字符 (glyph) 都儲存在這個表格內。每個字符僅僅紀錄了形狀,要知道某個編碼的某個字元 (character) 是對應到哪個形狀,還要透過 cmap這個表格來查詢;也有一個字沒有相對應的字符,或是沒有任何字對應到某個字符的情況。
參考資料:
Hinting (Instructing)
TrueType 是一種外框字型 (Outline Font),也就是說每一個字符都是以向量圖形的方式呈現,理論上可以在各種不同解析度下呈現相同的形狀。


但是越是在低解析度的時候,由於可用的像素較少,越容易遇到邊界的表達能力問題,如右圖的 M 字,若沒有對齊像素點的話,呈現出來的圖案就會比較瘦長且左右不對稱,如果稍微向右移動並加寬一點,呈現出來的圖案就會比較接近原本向量圖形所預期的形狀;這個動作正是 Hinting 中的對齊格線 (gridfitting) 功能。
在 TrueType 檔案中,描述 Hinting 的方式其實是儲存在字型的 fpgm 與prep 表格中的小程式,或是內嵌在字符中。看起來像是這樣:
PUSHB[000] # Push one byte onto the stack.
3 # Value for loop variable.
SLOOP[] # Set the loop count to 3.
PUSHB[002] # Push three bytes onto the stack.
5 # Point number.
46 # Point number.
43 # Point number.
ALIGNRP[] # Align the points 5, 46 and 43 with rp0 (point 8). This will
# align the height of the two lower serifs.
使用這個小程式的方法是 Apple 的專利,但是因為 TrueType 一開始只是業界標準,Apple 並沒有在規格書裡面提及專利的相關資訊,造成後來使用 FreeType啟用 BCI (Byte Code Interpreter) 可能會侵犯專利的問題。(相關專利已經在 2010 年 4 月全數過期)
對每個字符做 Hinting 是個耗時耗力的工作,就算是只有數百個字符的西文字型也要花上數倍於繪圖的時間來做 Hinting,因此除了少數高品質的字型外,多數的字型是沒有 Hinting 的。而隨著顯示裝置的解析度越來越高,對於Hinting 的需求也越來越少,在較新的作業系統上可能會忽略部份 Hinting 的資訊或是完全關閉 Hinting。而在自由軟體的世界中,大多使用 FreeType的 Auto-Hinting 技術來支援解析度較低的顯示裝置。
參考資料:
MingLiu
細明體 (MingLiu) 與新細明體 (PMingLiu) 是華康 (DynaLab) 設計的字型,內建於 Microsoft 的作業系統中,使用非常廣泛。華康的字型使用了特殊的組字方式,似乎是為了從自有的字型資料轉換到 TrueType 才會使用這樣的方法。
首先,定義一組筆劃的字符,只用來組字,不對應到任何的編碼:
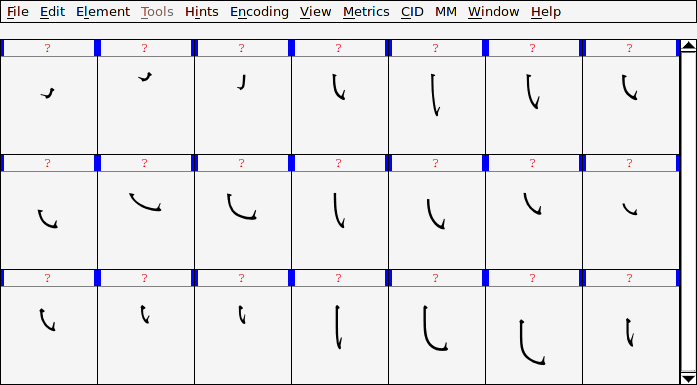
然後在每一個個別的字符中用參照的方式把筆劃匯入,這時筆劃間的相對位置是亂的,最後再用 Hinting 的功能把筆劃移動到對的位置去:
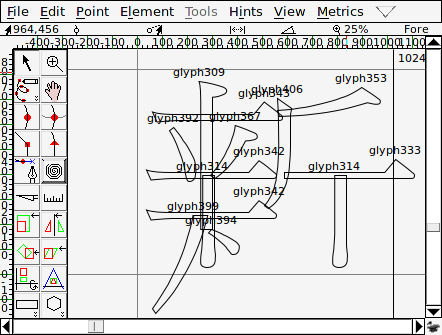
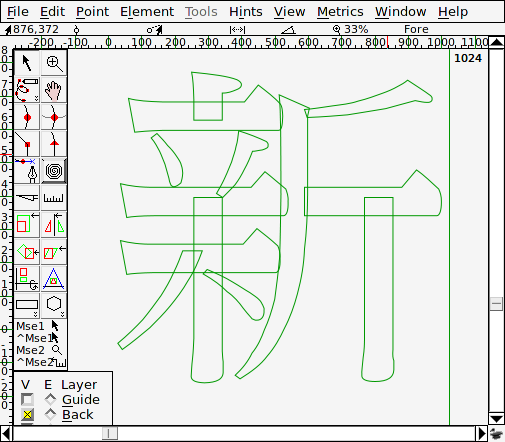
這樣濫用 Hinting 的方式,也導致如果不開啟 Hinting 就會看到破碎的字符:

為什麼說是濫用?因為只要沒有打開 Hinting 就會顯示錯誤,表示用錯地方了;有些時候是不需要,或是沒辦法使用 Hinting 的。
參考資料:
Tricky Fonts
除了新細明體,華康還有一些字型也是使用類似的方式組字,同樣很多人使用的標楷體就是其中之一,還有一些日本字型也是濫用 Hinting 的功能來繪製字符,所以 FreeType 其實有內建黑名單來對付這樣的字型,遇到了就強制開啟Hinting。一開始這個名單是用字型名稱來列表的:
static const char trick_names[TRICK_NAMES_COUNT]
[TRICK_NAMES_MAX_CHARACTERS + 1] =
{
"DFKaiSho-SB", /* dfkaisb.ttf */
"DFKaiShu",
"DFKai-SB", /* kaiu.ttf */
"HuaTianKaiTi?", /* htkt2.ttf */
"HuaTianSongTi?", /* htst3.ttf */
"MingLiU", /* mingliu.ttf & mingliu.ttc */
"PMingLiU", /* mingliu.ttc */
"MingLi43", /* mingli.ttf */
};
但是這樣還不夠,因為很多 PDF 輸出軟體會把字型的名稱亂改:
% pdffonts ~/pdf31yNwCi71d.pdf
name type emb sub uni object ID
------------------------------- ----------------- --- --- --- ---------
AAAAAA+TimesNewRoman TrueType yes yes yes 9 0
AAAAAB+___ TrueType yes yes yes 16 0
AAAAAC+___ TrueType yes yes yes 17 0
AAAAAE+____ TrueType yes yes yes 18 0
AAAAAD+____ TrueType yes yes yes 19 0
遇到這樣的情況就破功了,所以很多人在看 PDF 的時候會遇到字破掉的問題,我先在信中提出可能的解法,後來發現 Suzuki Toshiya 在 2010-11-22 的時候加入用 cvt/fpgm/prep 表格的加總檢查來比對黑名單,因為這三個表格是只要是有使用 Hinting 的字型都會有,也不太會改變的。
static const tt_sfnt_id_rec sfnt_id[TRICK_SFNT_IDS_NUM_FACES]
[TRICK_SFNT_IDS_PER_FACE] = {
...
{ /* MingLiU 1995 */
{ 0x05bcf058, 0x000002e4 }, /* cvt */
{ 0x28233bf1, 0x000087c4 }, /* fpgm */
{ 0xa344a1ea, 0x000001e1 } /* prep */
},
{ /* MingLiU 1996- */
{ 0x05bcf058, 0x000002e4 }, /* cvt */
{ 0x28233bf1, 0x000087c4 }, /* fpgm */
{ 0xa344a1eb, 0x000001e1 } /* prep */
},
...
只是原先這個方法只有在字型沒有名稱的時候才會啟用,我加了 patch 改成無條件檢查黑名單,從此就應該不會有漏網之魚了。
參考資料:
- Re: How to read Chinese PDFs anymore with xpdf?
- [truetype] Identify the tricky fonts by cvt/fpgm/prep checksums.
- [truetype] Always check the checksum to identify tricky fonts.
- [truetype] Revert the reordering of trickyness checking.
- [truetype] Register a set of tricky fonts, NEC FA family.
Sign Extension
只是後來我在我的機器上面仍然發現某些 PDF 仍然顯示破碎字型,難道是加總檢查也會出錯?因為牽扯到加總的問題,第一個想到的就是可能跟機器的整數長度有關,立刻改用 32-bit 的環境測試同一個 PDF,果然就好了。但是計算檢查碼的演算法很簡單,也沒有溢位的疑慮,那是哪裡出了問題?好在 IRC上有大大給了提示:
kanru> hum.. checksum *: 0xa344a1eb
kanru> checksum #: 0xffffffffa344a1eb
j5g> kanru: 哈,因為 init checksum = 0xffffffff, sign extension 變
成 0xffffffffffffffff?
j5g> 然後之後都只處理後面 32bit
kanru> j5g: 不過有可能是 font 裡面是錯的
kanru> 0xffffffffa344a1eb 是直接從 font table 讀出來的
j5g> 喔,那就是 0xa344a1eb sign extended to 0xffffffffa344a1eb
原來是 FreeType 在讀入字型資訊的時候,強制把 int 轉型為 uint 結果發生sign extension 錯誤,之後比對的時候就跟著錯了。送了 patch 之後,應該天下太平了吧?
參考資料:
PDF correctness
有人問說:那為什麼不乾脆隨時打開 Hinting 就好?據我所知目前的自由 PDFViewer 都是預設關閉 Hinting 的,除了上述的理由外,我猜大概是因為Hinting 有可能大幅度的改變一個字符的寬度,如下圖:

可以發現三種顯示方式的寬度都不一樣,而 PDF 是一種接近印刷品質的檔案格式,有可能在輸出 PDF 的時候已經丟失動態改變寬度的能力,kern 的修正也已經沒辦法修改,這時候如過還讓 Hinting 去改變字符的寬度的話,很有可能得到不理想的結果。不過以上只是我的猜想,還沒有找各 PDF Viewer 的作者證實。至於封閉的商業 PDF Viewer 又是怎麼做的就更不得而知了。
結論:快升級到最新的 FreeType 吧!如果還有遇到顯示錯誤的 PDF 可以寄給我,如果以上筆記有疏漏錯誤的地方歡迎指正 ?
Speed comparison C vs Common Lisp
昨天看到有人轉噗一則 StackOverflow 上面的問題,內容是問他分別用 C,
python, erlang 與 haskell 寫了 Project Euler 的第十二題,但是
haskell 版本慢得不像話,該如何改進?
以下是苦主的原始 C 語言版:
#include <stdio.h>
#include <math.h>
int factorCount (long n)
{
double square = sqrt (n);
int isquare = (int) square;
int count = isquare == square ? -1 : 0;
long candidate;
for (candidate = 1; candidate <= isquare; candidate ++)
if (0 == n % candidate) count += 2;
return count;
}
int main ()
{
long triangle = 1;
int index = 1;
while (factorCount (triangle) < 1001)
{
index ++;
triangle += index;
}
printf ("%ld\n", triangle);
}
我的執行時間約為 5.48s
% gcc -lm -o euler12.bin euler12.c
% time ./euler12.bin
842161320
./euler12.bin 5.48s user 0.00s system 99% cpu 5.484 total
手癢想看看據說可以編譯出不錯的機器碼的 Common Lisp 速度怎麼樣,於是第
一個版本如下 (用 sbcl 執行):
(defun factor-count (n)
(let* ((square (sqrt n))
(squaref (floor square))
(count (if (eql squaref square) -1 0)))
(loop
for cand from 1 to squaref
count (eql 0 (rem n cand)) into c
finally (return (+ count c c)))))
(defun first-triangle-over (n)
(loop
for idx from 1
sum idx into triangle
until (>= (factor-count triangle) n)
finally (return triangle)))
;; (time (first-triangle-over 1000))
;; Evaluation took:
;; 11.192 seconds of real time
;; 11.184699 seconds of total run time (11.184699 user, 0.000000 system)
;; 99.94% CPU
;; 30,135,882,489 processor cycles
;; 32,912 bytes consed
;;
;; 842161320
還不錯,11.192s,這個版本採用原文中給 haskell 的建議,使用 rem 而不是 mod,可以
加快一點速度。再給一點關於型別的提示,然後把第一個 function inline,第
二版可以跑出和 C 版本差不多的成績 5.563s 🙂
(declaim (inline factor-count)) ;; <----
(defun factor-count (n)
(let* ((square (sqrt n))
(squaref (floor square))
(count (if (eql squaref square) -1 0)))
(loop
for cand from 1 to squaref
count (eql 0 (rem n cand)) into c
finally (return (+ count c c)))))
(defun first-triangle-over (n)
(loop
for idx of-type fixnum from 1 ;; <----
sum idx into triangle of-type fixnum ;; <----
until (>= (factor-count triangle) n)
finally (return triangle)))
;; (time (first-triangle-over 1000))
;; Evaluation took:
;; 5.563 seconds of real time
;; 5.556347 seconds of total run time (5.556347 user, 0.000000 system)
;; 99.87% CPU
;; 14,970,270,903 processor cycles
;; 32,768 bytes consed
;;
;; 842161320
純粹湊個熱鬧而已,有興趣的人可以試試看把 loop 改成和原文其他語言一樣使
用遞迴來實做,大部分 Lisp 都有做 TCO,速度應該差不多…
結論:Common Lisp is awesome 😉